5. Anatomy of a Parquet File¶
This is a minimal overview of Parquet. For full details, see the Apache Parquet documentation.
5.1 The schema¶
Parquet files contain a physical data schema defining how their data columns are encoded as bytes on disk. This schema supports arbitrary levels of nullability, nesting (groups), and repetition (lists). These physical data types may also be mapped to one or more logical types. Parquet stores all data in little endian byte order.
There is a broader many-to-many mapping between Parquet schemas and Apache Arrow schemas. Arrow supports many types that Parquet does not, but the two share a common abstraction of columnar storage with per-value nullability. Although they represent these concepts differently, conversion between them is straightforward.
5.2 The metadata key–value pairs¶
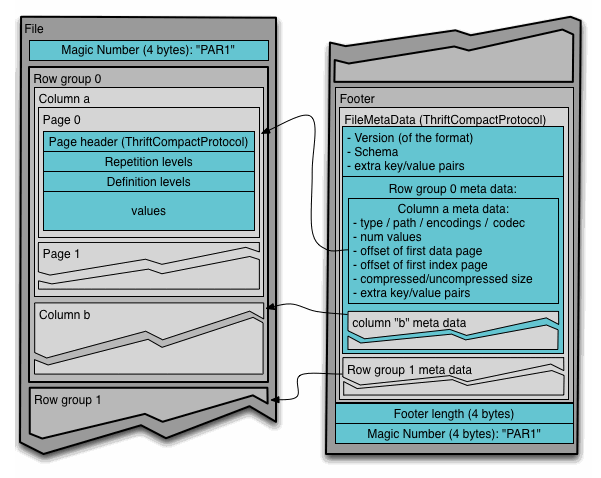
At the end of a Parquet file is a footer containing user-defined metadata along with the file's schema, offsets, and search indices. This user-defined metadata is stored as key–value pairs, which makes it well suited to carrying light-weight, immediately useful metadata that does not make sense to force into the data columns. mzPeak uses this footer extensively — most notably for the array index.
5.3 The columnar data¶
Parquet is a strongly typed binary columnar format with layered, blocked compression that permits a degree of random access.
Support both 32-bit and 64-bit collection types
Because some languages have no concept of 64-bit addresses, all
implementations MUST handle both the large_* and non-large_*
variants of collection types: list, string, and binary.
5.3.1 Row groups and pages¶
A Parquet file is divided into row groups, each of which stores a horizontal slice of every column as a column chunk. Column chunks are further divided into pages, the smallest unit of compression and encoding. This hierarchy is what lets a reader retrieve a narrow slice of a large file: it can locate the row group and pages that hold the rows of interest and read only those.
Choosing row-group and page sizes trades compression ratio against random-access granularity — larger groups compress better but make fine-grained reads coarser.
Open item — tuning guidance
Concrete recommendations for balancing compression against random-access granularity (row-group size, page size, dictionary page size) are still being collected and will be expanded in a future revision.
5.3.2 Index levels¶
When writing an mzPeak archive, the writer MUST write a
page index. Most
libraries that write Parquet support writing the page index even if they do not
themselves use it when reading. The page index records per-page value ranges,
which is what makes predicate-driven reads (for example, "only pages whose
spectrum_index covers 5000–5100") efficient.